Note: As a priority, this analyses were run using only those with a diagnosis of congenital hypotonia.
Setup details
library(ASQ3)
library(data.table)
dataset <- dataset[diagnostico %like% "hipotonia"]
# Round to nearest multiple
near <- function(i, j) {
stopifnot("'i' must be a number" = is.numeric(i),
"'j' must be a number" = is.numeric(j))
i_hat = i / j
output = round(i_hat) * j
return(output)
}
# Plot GAM model of bivariate model
plot_gam <- function(data, x, y, xlab, ylab, round_to = 1, ...) {
if (missing(xlab)) xlab <- deparse(substitute(x))
if (missing(ylab)) ylab <- deparse(substitute(y))
scaled = copy(data)
if (round_to > 1) {
j_exec = substitute(near(x, round_to))
x_var = deparse(substitute(x))
scaled[, (x_var) := eval(j_exec)]
}
ggplot2::ggplot(data, ggplot2::aes({{x}}, {{y}})) +
ggplot2::geom_count(alpha = 0.1) +
ggplot2::stat_summary(data = scaled, fun.data = ggplot2::mean_se) +
ggplot2::geom_smooth(method = "gam",
formula = y ~ s(x),
col = "red4",
method.args = list(...)) +
ggplot2::labs(x = xlab, y = ylab, caption = paste0("Mean ± SE in ", round_to, "-unit intervals")) +
see::theme_lucid()
}Working with first assessment
For this page, we’ll be fitting different models using generalized
additive models (GAM’s) using the mgcv package for modeling
non-linear relationships, even though it can be used to model linear
relationships too. The smoothing parameter (the one that gets to decide
how wiggly will be the curve) will be estimated using restricted maximum
likelihood (i.e., REML).
About interpretation
The interpretation of the summary of GAM models in R can be seen in this short video (~ 4 minutes) from datacamp. However, let’s get a short intro to a fast interpretation!
Approximate significance of smooth terms:
edf Ref.df F p-value
s(edad_cronologica_meses) 6.475 7.561 28.98 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1This small part of a summary output shows that the influence of
edad_cronologica_meses is significant at a p-value of
<2e-16. The edf stands for “Effective Degrees of
Freedom” and reflects how complex (or wiggly) the relationship is. Thus,
an edf of 1 reflects a linear relationship, while and
edf of 2 reflects a cuadratic relationship, an
edf of 3 cubic relationship and so on.
More information about GAMs can be seen here:
Modeling
Communication score & chronological age (in months)
Model: comunicacion_total ~ edad_cronologica_meses
plot_gam(data = dataset[n_evaluacion == 1 & edad_cronologica_meses <= 60],
x = edad_cronologica_meses,
y = comunicacion_total,
ylab = "Communication",
xlab = "Months old",
round_to = 5,
method = "REML")
#> Warning: Removed 2 rows containing missing values (geom_segment).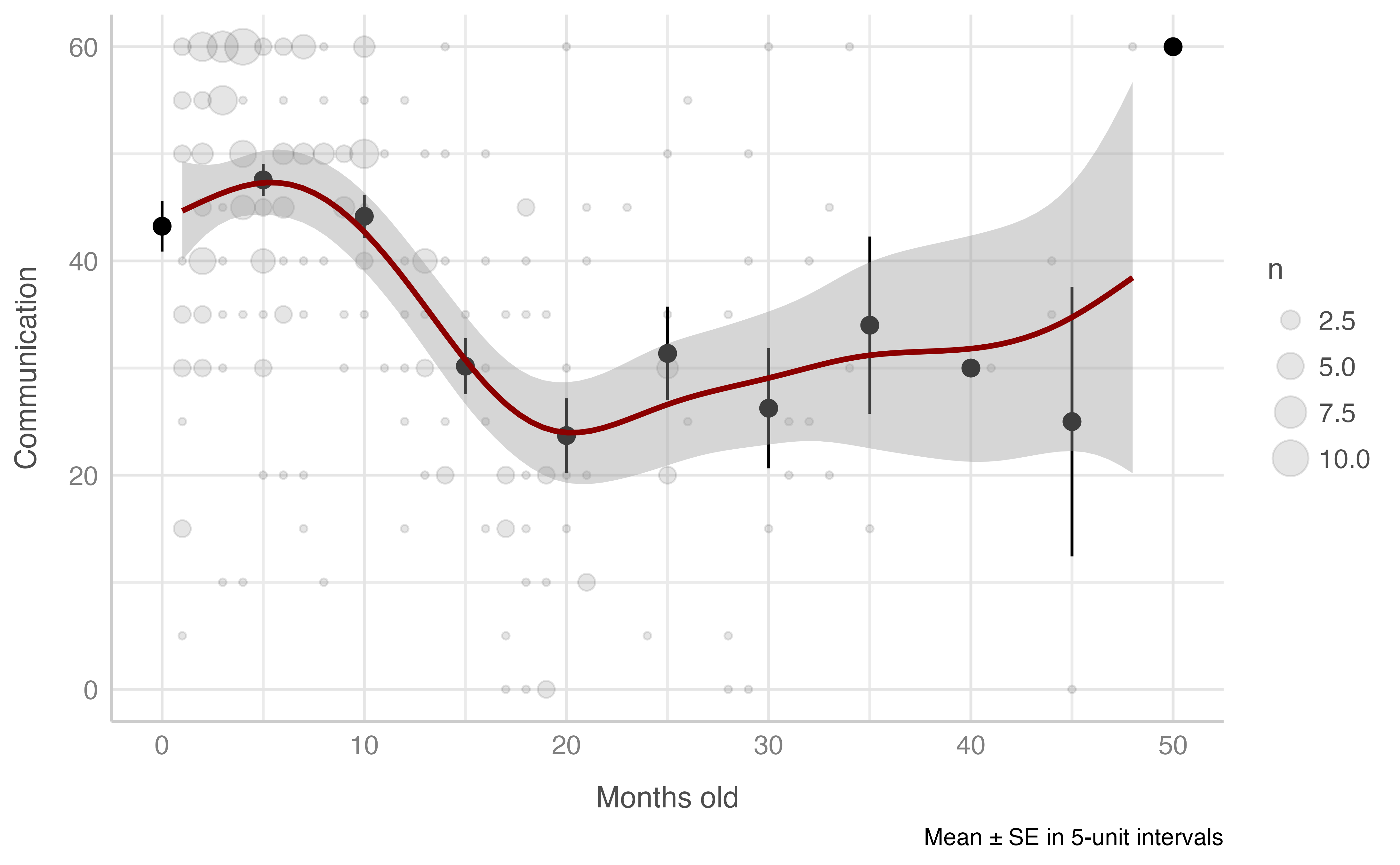
library(mgcv)
#> Loading required package: nlme
#> This is mgcv 1.8-40. For overview type 'help("mgcv-package")'.
mgcv::gam(formula = comunicacion_total ~ s(edad_cronologica_meses),
data = dataset[n_evaluacion == 1 & edad_cronologica_meses <= 60],
method = "REML") |>
summary()
#>
#> Family: gaussian
#> Link function: identity
#>
#> Formula:
#> comunicacion_total ~ s(edad_cronologica_meses)
#>
#> Parametric coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 39.4017 0.9242 42.63 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Approximate significance of smooth terms:
#> edf Ref.df F p-value
#> s(edad_cronologica_meses) 5.079 6.142 14.54 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> R-sq.(adj) = 0.276 Deviance explained = 29.2%
#> -REML = 954.54 Scale est. = 199.86 n = 234Problem solving score & chronological age (in months)
Model: resolucion_problemas_total ~ edad_cronologica_meses
plot_gam(data = dataset[n_evaluacion == 1 & edad_cronologica_meses <= 60],
x = edad_cronologica_meses,
y = resolucion_problemas_total,
ylab = "Problem solving",
xlab = "Months old",
round_to = 5,
method = "REML")
#> Warning: Removed 2 rows containing missing values (geom_segment).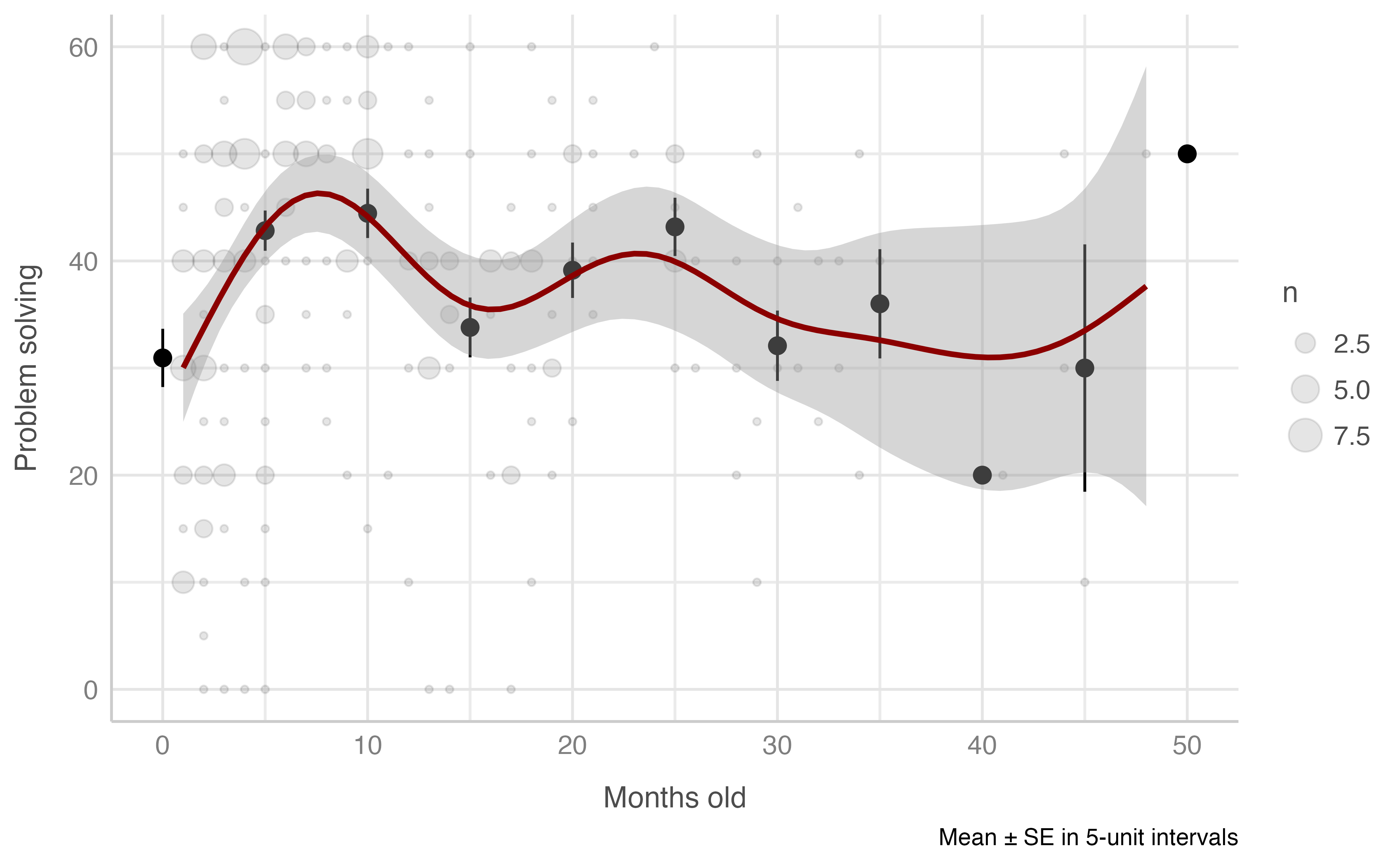
mgcv::gam(formula = resolucion_problemas_total ~ s(edad_cronologica_meses),
data = dataset[n_evaluacion == 1 & edad_cronologica_meses <= 60],
method = "REML") |>
summary()
#>
#> Family: gaussian
#> Link function: identity
#>
#> Formula:
#> resolucion_problemas_total ~ s(edad_cronologica_meses)
#>
#> Parametric coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 38.8034 0.9663 40.16 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Approximate significance of smooth terms:
#> edf Ref.df F p-value
#> s(edad_cronologica_meses) 5.818 6.938 3.946 0.000467 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> R-sq.(adj) = 0.104 Deviance explained = 12.6%
#> -REML = 966.37 Scale est. = 218.47 n = 234Communication score & corrected age (in months)
Model: comunicacion_total ~ edad_corregida_meses
plot_gam(data = dataset[n_evaluacion == 1 & edad_corregida_meses <= 60],
x = edad_corregida_meses,
y = comunicacion_total,
ylab = "Communication",
xlab = "Corrected age (months old)",
round_to = 5,
method = "REML")
#> Warning: Removed 2 rows containing missing values (geom_segment).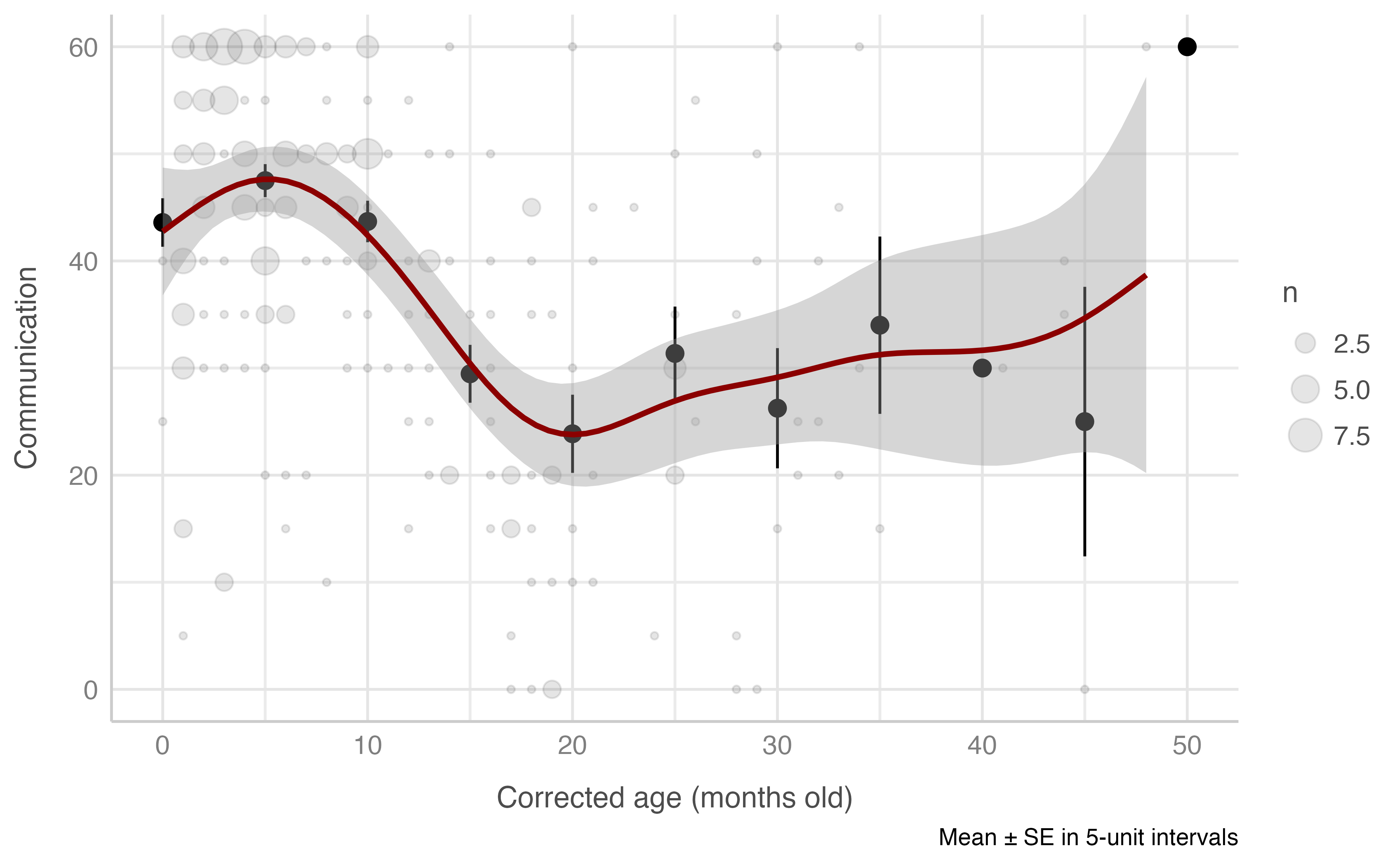
mgcv::gam(formula = comunicacion_total ~ s(edad_corregida_meses),
data = dataset[n_evaluacion == 1 & edad_corregida_meses <= 60],
method = "REML") |>
summary()
#>
#> Family: gaussian
#> Link function: identity
#>
#> Formula:
#> comunicacion_total ~ s(edad_corregida_meses)
#>
#> Parametric coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 39.4017 0.9234 42.67 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Approximate significance of smooth terms:
#> edf Ref.df F p-value
#> s(edad_corregida_meses) 5.252 6.338 14.12 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> R-sq.(adj) = 0.277 Deviance explained = 29.3%
#> -REML = 954.67 Scale est. = 199.55 n = 234Fine motor skills score & corrected age (in months)
Model: motora_fina_total ~ edad_corregida_meses
plot_gam(data = dataset[n_evaluacion == 1 & edad_corregida_meses <= 60],
x = edad_corregida_meses,
y = motora_fina_total,
ylab = "Fine motor skills",
xlab = "Corrected age (months old)",
round_to = 5,
method = "REML")
#> Warning: Removed 2 rows containing missing values (geom_segment).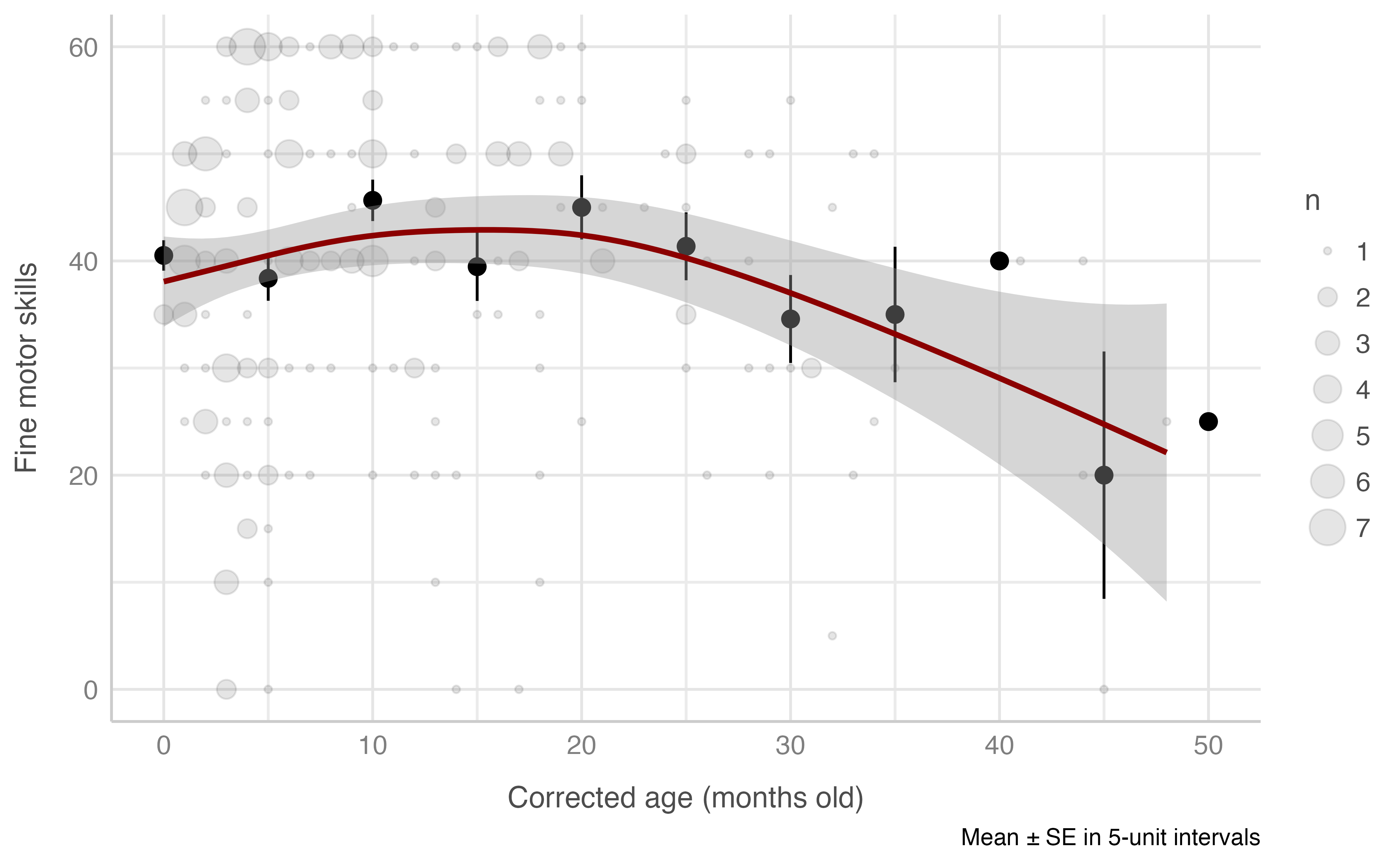
mgcv::gam(formula = motora_fina_total ~ s(edad_corregida_meses),
data = dataset[n_evaluacion == 1 & edad_corregida_meses <= 60],
method = "REML") |>
summary()
#>
#> Family: gaussian
#> Link function: identity
#>
#> Formula:
#> motora_fina_total ~ s(edad_corregida_meses)
#>
#> Parametric coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 40.256 0.962 41.85 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Approximate significance of smooth terms:
#> edf Ref.df F p-value
#> s(edad_corregida_meses) 2.608 3.256 3.344 0.0175 *
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> R-sq.(adj) = 0.0413 Deviance explained = 5.21%
#> -REML = 959.89 Scale est. = 216.56 n = 234Problem solving score & corrected age (in months)
Model: resolucion_problemas_total ~ edad_corregida_meses
plot_gam(data = dataset[n_evaluacion == 1 & edad_corregida_meses <= 60],
x = edad_corregida_meses,
y = resolucion_problemas_total,
ylab = "Fine motor skills",
xlab = "Corrected age (months old)",
round_to = 5,
method = "REML")
#> Warning: Removed 2 rows containing missing values (geom_segment).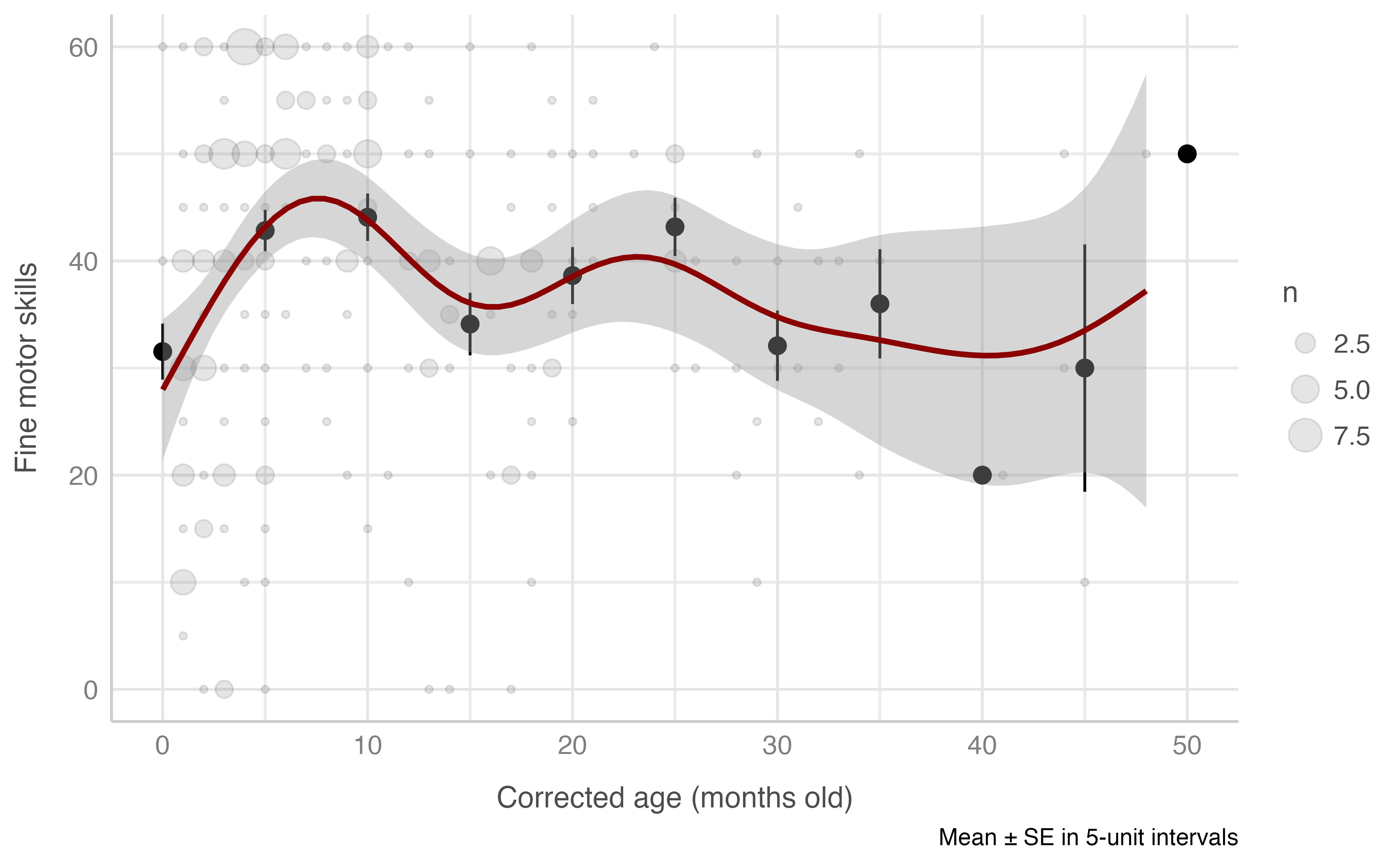
mgcv::gam(formula = resolucion_problemas_total ~ s(edad_corregida_meses),
data = dataset[n_evaluacion == 1 & edad_corregida_meses <= 60],
method = "REML") |>
summary()
#>
#> Family: gaussian
#> Link function: identity
#>
#> Formula:
#> resolucion_problemas_total ~ s(edad_corregida_meses)
#>
#> Parametric coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 38.8034 0.9715 39.94 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Approximate significance of smooth terms:
#> edf Ref.df F p-value
#> s(edad_corregida_meses) 5.66 6.776 3.638 0.00121 **
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> R-sq.(adj) = 0.0942 Deviance explained = 11.6%
#> -REML = 967.27 Scale est. = 220.86 n = 234Socio-individual skills score & corrected age (in months)
Model: socio_individual_total ~ edad_corregida_meses
plot_gam(data = dataset[n_evaluacion == 1 & edad_corregida_meses <= 60],
x = edad_corregida_meses,
y = socio_individual_total,
ylab = "Socio-individual skills",
xlab = "Corrected age (months old)",
round_to = 4,
method = "REML")
#> Warning: Removed 3 rows containing missing values (geom_segment).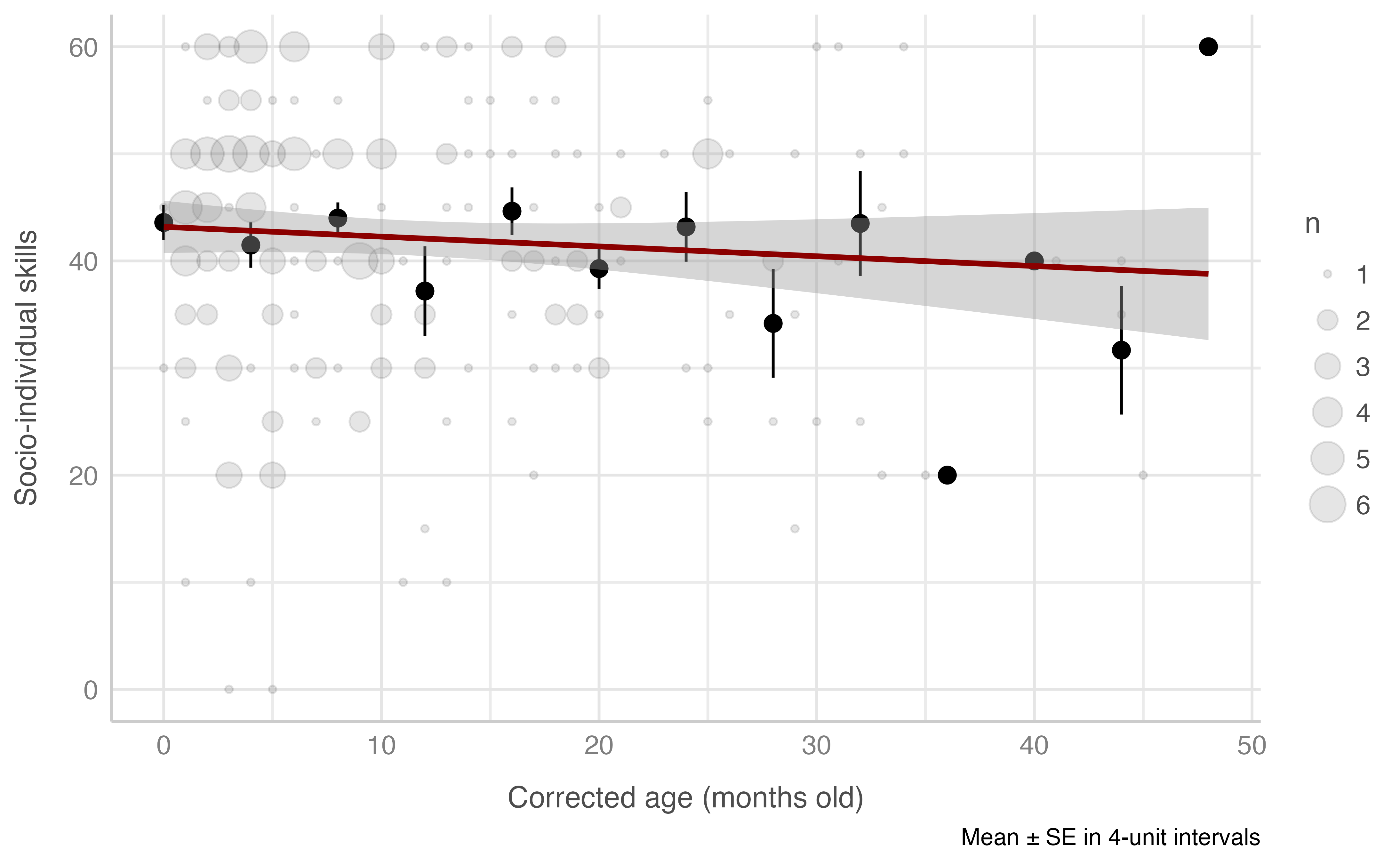
mgcv::gam(formula = socio_individual_total ~ s(edad_corregida_meses),
data = dataset[n_evaluacion == 1 & edad_corregida_meses <= 60],
method = "REML") |>
summary()
#>
#> Family: gaussian
#> Link function: identity
#>
#> Formula:
#> socio_individual_total ~ s(edad_corregida_meses)
#>
#> Parametric coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 42.1581 0.8288 50.87 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Approximate significance of smooth terms:
#> edf Ref.df F p-value
#> s(edad_corregida_meses) 1.001 1.001 1.222 0.27
#>
#> R-sq.(adj) = 0.000957 Deviance explained = 0.525%
#> -REML = 923.89 Scale est. = 160.73 n = 234Communication score & developmental ASQ-3 age (in months)
Model: comunicacion_total ~ asq3_meses
plot_gam(data = dataset[n_evaluacion == 1],
x = asq3_meses,
y = comunicacion_total,
ylab = "Communication",
xlab = "developmental ASQ-3 age (months old)",
round_to = 5,
method = "REML")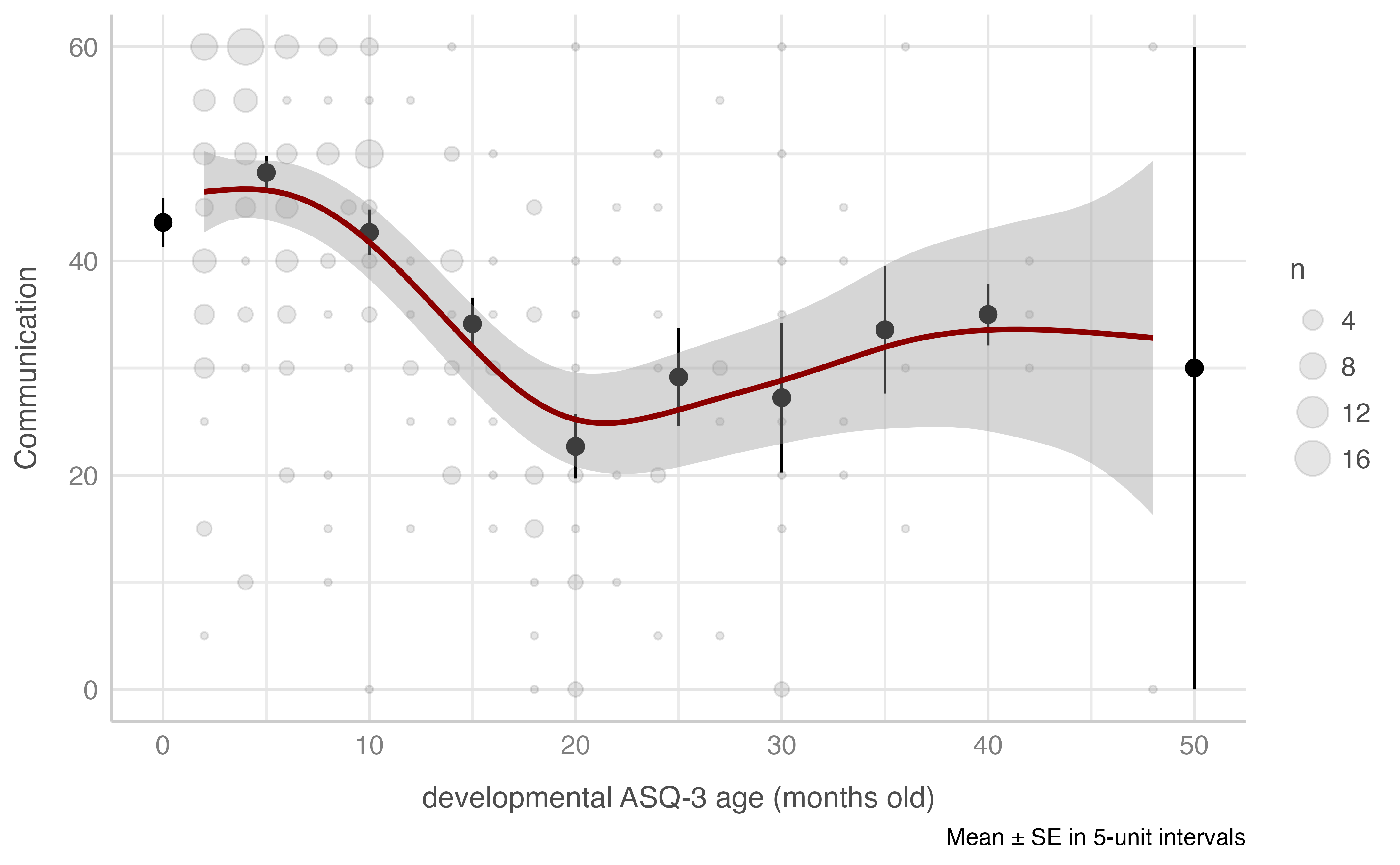
mgcv::gam(formula = comunicacion_total ~ s(asq3_meses),
data = dataset[n_evaluacion == 1],
method = "REML") |>
summary()
#>
#> Family: gaussian
#> Link function: identity
#>
#> Formula:
#> comunicacion_total ~ s(asq3_meses)
#>
#> Parametric coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 39.4017 0.9382 42 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Approximate significance of smooth terms:
#> edf Ref.df F p-value
#> s(asq3_meses) 4.523 5.543 14.43 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> R-sq.(adj) = 0.254 Deviance explained = 26.8%
#> -REML = 956.93 Scale est. = 205.96 n = 234Problem solving score & developmental ASQ-3 age (in months)
Model: resolucion_problemas_total ~ asq3_meses
plot_gam(data = dataset[n_evaluacion == 1],
x = asq3_meses,
y = resolucion_problemas_total,
ylab = "Problem solving",
xlab = "developmental ASQ-3 age (months old)",
round_to = 5,
method = "REML")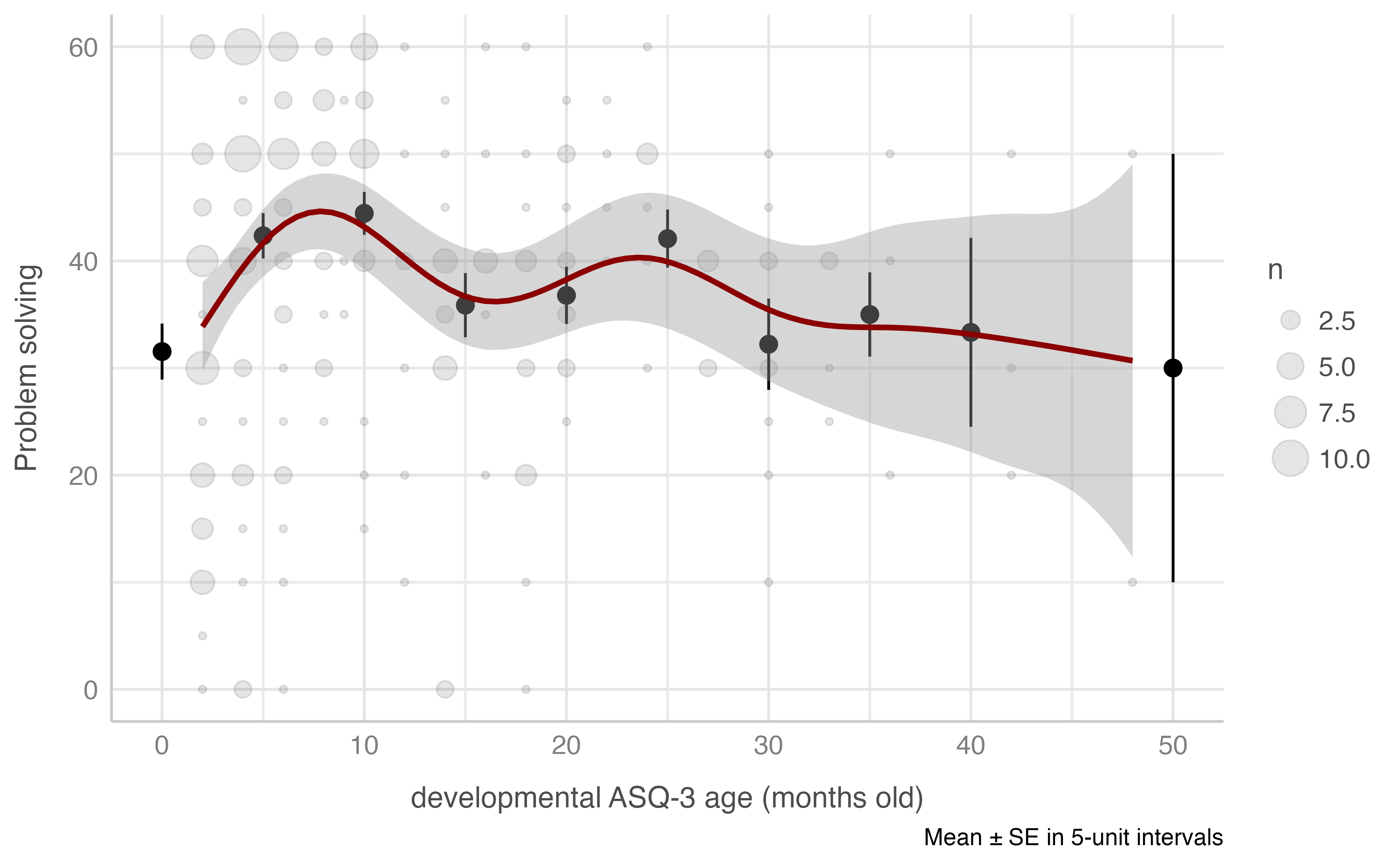
mgcv::gam(formula = resolucion_problemas_total ~ s(asq3_meses),
data = dataset[n_evaluacion == 1],
method = "REML") |>
summary()
#>
#> Family: gaussian
#> Link function: identity
#>
#> Formula:
#> resolucion_problemas_total ~ s(asq3_meses)
#>
#> Parametric coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 38.8034 0.9843 39.42 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Approximate significance of smooth terms:
#> edf Ref.df F p-value
#> s(asq3_meses) 5.392 6.52 2.724 0.0104 *
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> R-sq.(adj) = 0.0703 Deviance explained = 9.18%
#> -REML = 969.65 Scale est. = 226.71 n = 234Fine motor skills score & developmental ASQ-3 age (in months)
Model: motora_fina_total ~ asq3_meses
plot_gam(data = dataset[n_evaluacion == 1],
x = asq3_meses,
y = motora_fina_total,
ylab = "Fine motor skills",
xlab = "developmental ASQ-3 age (months old)",
round_to = 5,
method = "REML")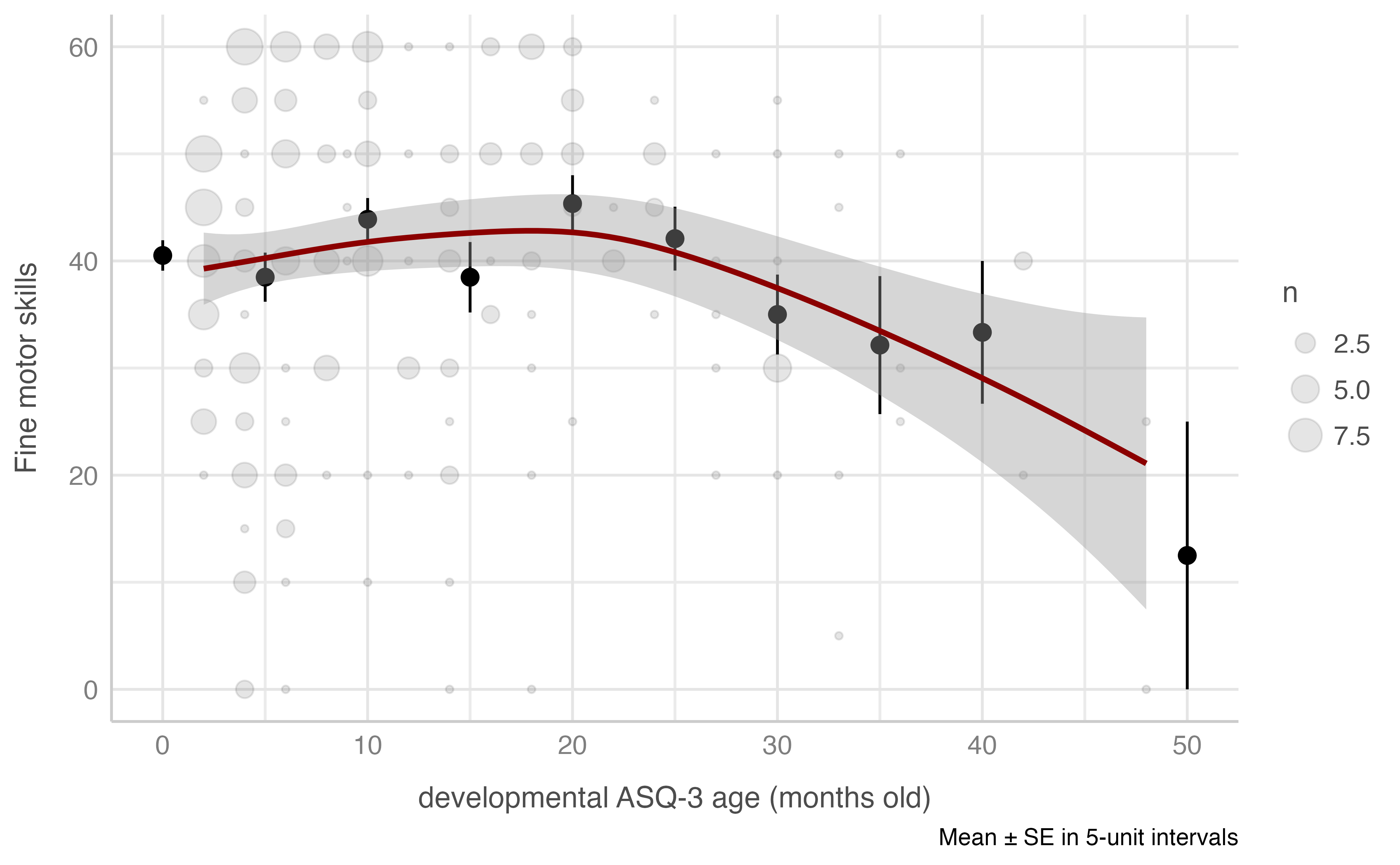
mgcv::gam(formula = motora_fina_total ~ s(asq3_meses),
data = dataset[n_evaluacion == 1],
method = "REML") |>
summary()
#>
#> Family: gaussian
#> Link function: identity
#>
#> Formula:
#> motora_fina_total ~ s(asq3_meses)
#>
#> Parametric coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 40.2564 0.9621 41.84 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Approximate significance of smooth terms:
#> edf Ref.df F p-value
#> s(asq3_meses) 2.623 3.281 3.271 0.0188 *
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> R-sq.(adj) = 0.0412 Deviance explained = 5.2%
#> -REML = 959.92 Scale est. = 216.59 n = 234Fine motor skills score & Communication score
Model: motora_fina_total ~ comunicacion_total
plot_gam(data = dataset[n_evaluacion == 1],
x = comunicacion_total,
y = motora_fina_total,
ylab = "Fine motor skills",
xlab = "Communication",
round_to = 5,
method = "REML")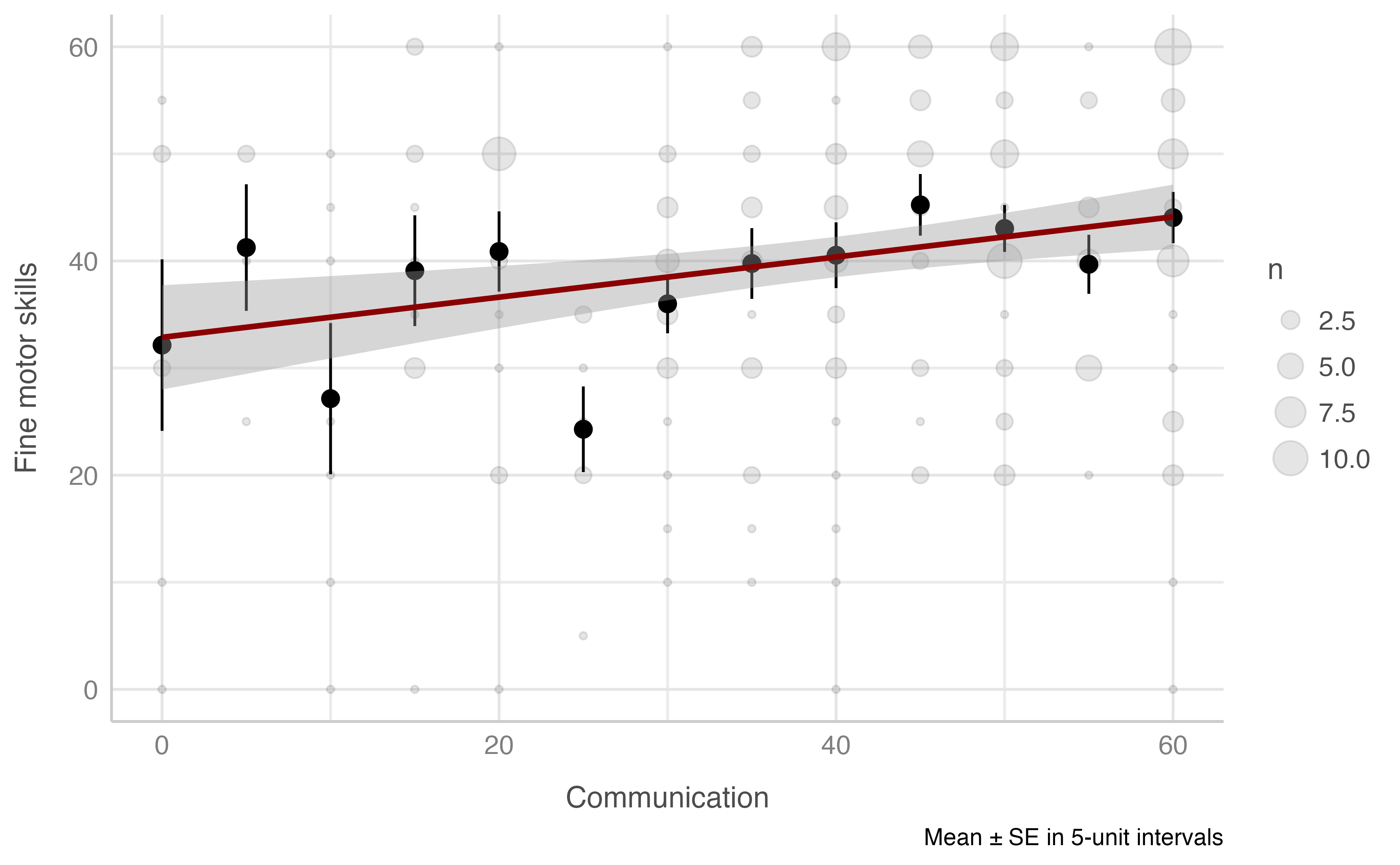
mgcv::gam(formula = motora_fina_total ~ s(comunicacion_total),
data = dataset[n_evaluacion == 1],
method = "REML") |>
summary()
#>
#> Family: gaussian
#> Link function: identity
#>
#> Formula:
#> motora_fina_total ~ s(comunicacion_total)
#>
#> Parametric coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 40.2564 0.9633 41.79 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Approximate significance of smooth terms:
#> edf Ref.df F p-value
#> s(comunicacion_total) 1.001 1.001 10.4 0.00143 **
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> R-sq.(adj) = 0.0388 Deviance explained = 4.3%
#> -REML = 958.78 Scale est. = 217.12 n = 234Socio-individual skills score & Communication score
Model: socio_individual_total ~ comunicacion_total
plot_gam(data = dataset[n_evaluacion == 1],
x = comunicacion_total,
y = socio_individual_total,
ylab = "Socio-individual skills",
xlab = "Communication",
round_to = 5,
method = "REML")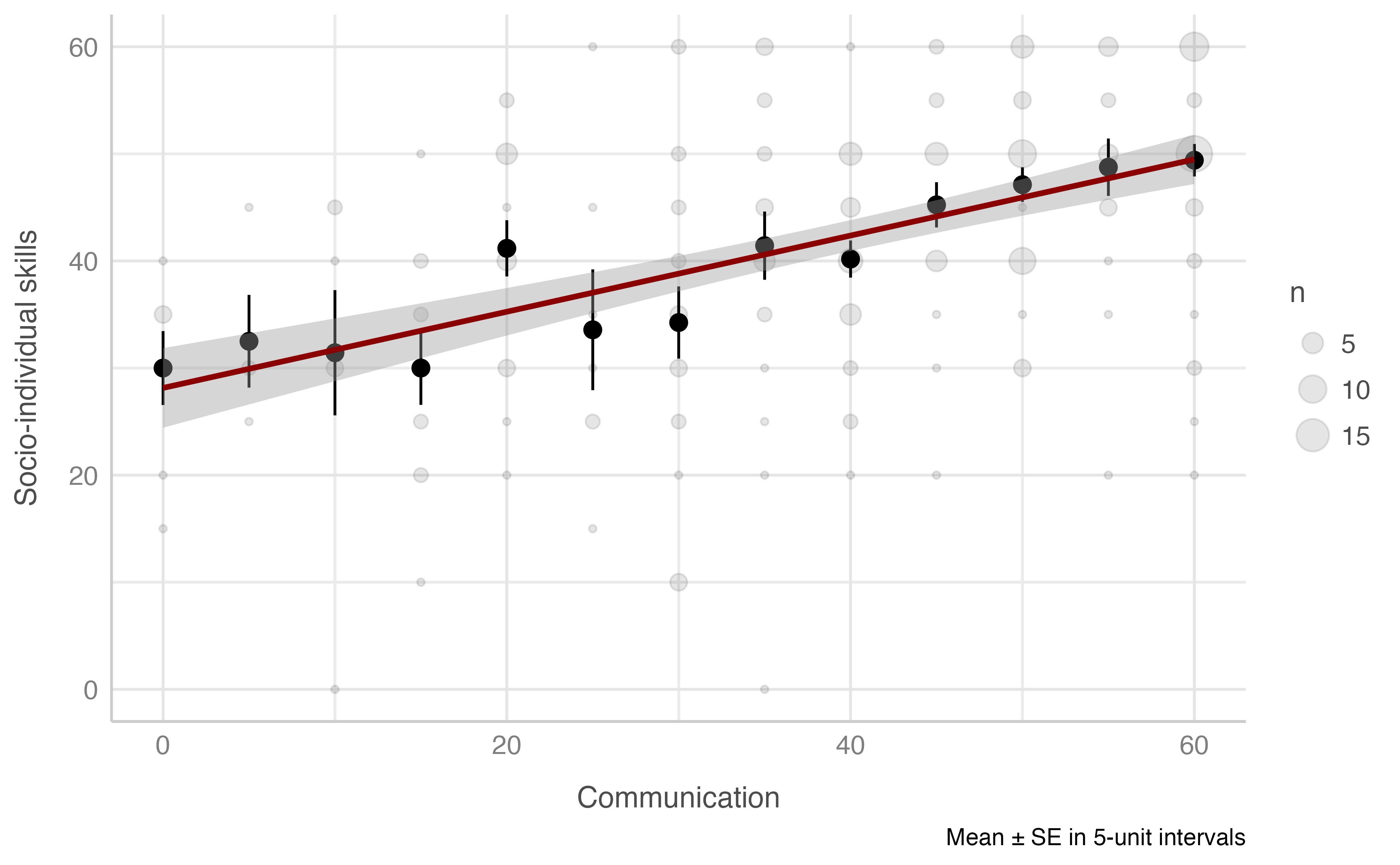
mgcv::gam(formula = socio_individual_total ~ s(comunicacion_total),
data = dataset[n_evaluacion == 1],
method = "REML") |>
summary()
#>
#> Family: gaussian
#> Link function: identity
#>
#> Formula:
#> socio_individual_total ~ s(comunicacion_total)
#>
#> Parametric coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 42.1581 0.7353 57.34 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Approximate significance of smooth terms:
#> edf Ref.df F p-value
#> s(comunicacion_total) 1 1.001 64.28 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> R-sq.(adj) = 0.214 Deviance explained = 21.7%
#> -REML = 896.12 Scale est. = 126.5 n = 234Gross motor skills score score & Communication score
Model: motora_gruesa_total ~ comunicacion_total
plot_gam(data = dataset[n_evaluacion == 1],
x = comunicacion_total,
y = motora_gruesa_total,
ylab = "Gross motor skills",
xlab = "Communication",
round_to = 5,
method = "REML")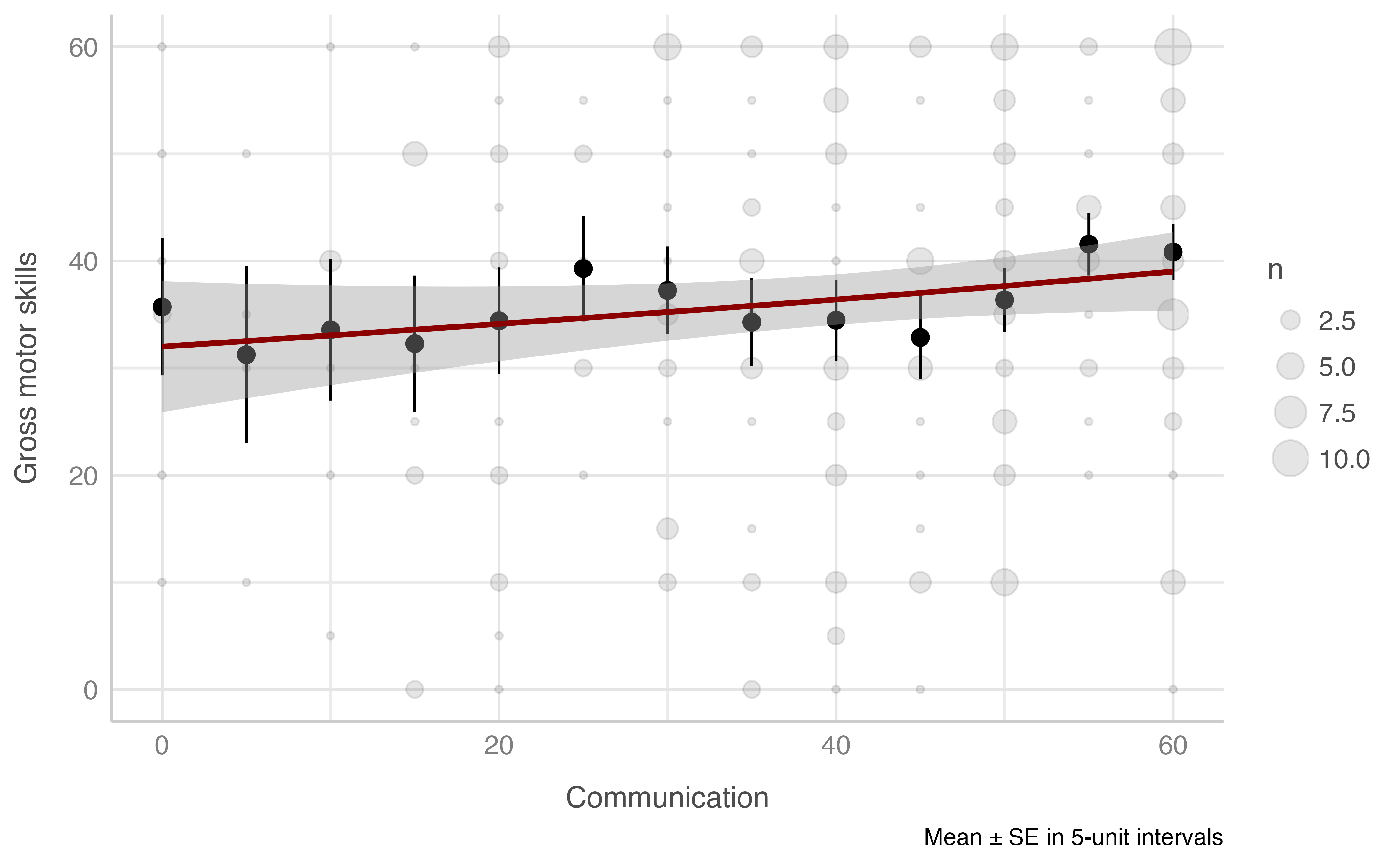
mgcv::gam(formula = motora_gruesa_total ~ s(comunicacion_total),
data = dataset[n_evaluacion == 1],
method = "REML") |>
summary()
#>
#> Family: gaussian
#> Link function: identity
#>
#> Formula:
#> motora_gruesa_total ~ s(comunicacion_total)
#>
#> Parametric coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 36.43 1.15 31.69 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Approximate significance of smooth terms:
#> edf Ref.df F p-value
#> s(comunicacion_total) 1.096 1.186 2.254 0.108
#>
#> R-sq.(adj) = 0.00871 Deviance explained = 1.34%
#> -REML = 999.87 Scale est. = 309.28 n = 234Looks more like a linear relationship than a non-linear one. This is notorious when we look at the effective degrees of freedom (edf), i.e. the closer to 1 more alike to a linear regression. Although is not significant at a 5% level.
Problem solving score & Fine motor skills score
Model: resolucion_problemas_total ~ motora_fina_total
plot_gam(data = dataset[n_evaluacion == 1],
x = motora_fina_total,
y = resolucion_problemas_total,
ylab = "Problem solving",
xlab = "Fine motor skills",
round_to = 5,
method = "REML")
#> Warning: Removed 1 rows containing missing values (geom_segment).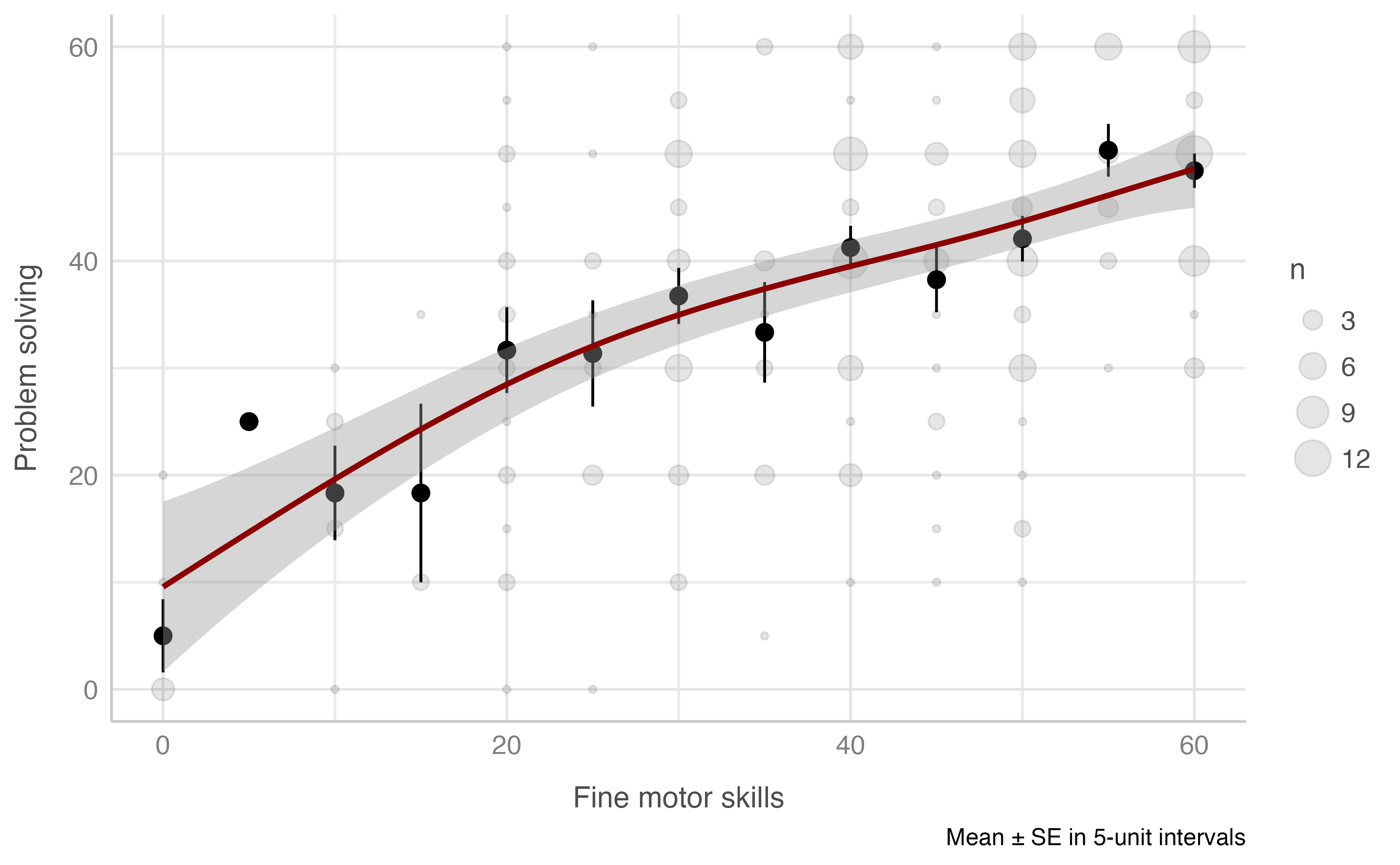
mgcv::gam(formula = resolucion_problemas_total ~ s(motora_fina_total),
data = dataset[n_evaluacion == 1],
method = "REML") |>
summary()
#>
#> Family: gaussian
#> Link function: identity
#>
#> Formula:
#> resolucion_problemas_total ~ s(motora_fina_total)
#>
#> Parametric coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 38.8034 0.8569 45.28 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Approximate significance of smooth terms:
#> edf Ref.df F p-value
#> s(motora_fina_total) 2.53 3.155 31.25 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> R-sq.(adj) = 0.295 Deviance explained = 30.3%
#> -REML = 932.96 Scale est. = 171.84 n = 234Socio-individual skills score & Fine motor skills score
Model: socio_individual_total ~ motora_fina_total
plot_gam(data = dataset[n_evaluacion == 1],
x = motora_fina_total,
y = socio_individual_total,
ylab = "Socio-individual skills",
xlab = "Fine motor skills",
round_to = 5,
method = "REML")
#> Warning: Removed 1 rows containing missing values (geom_segment).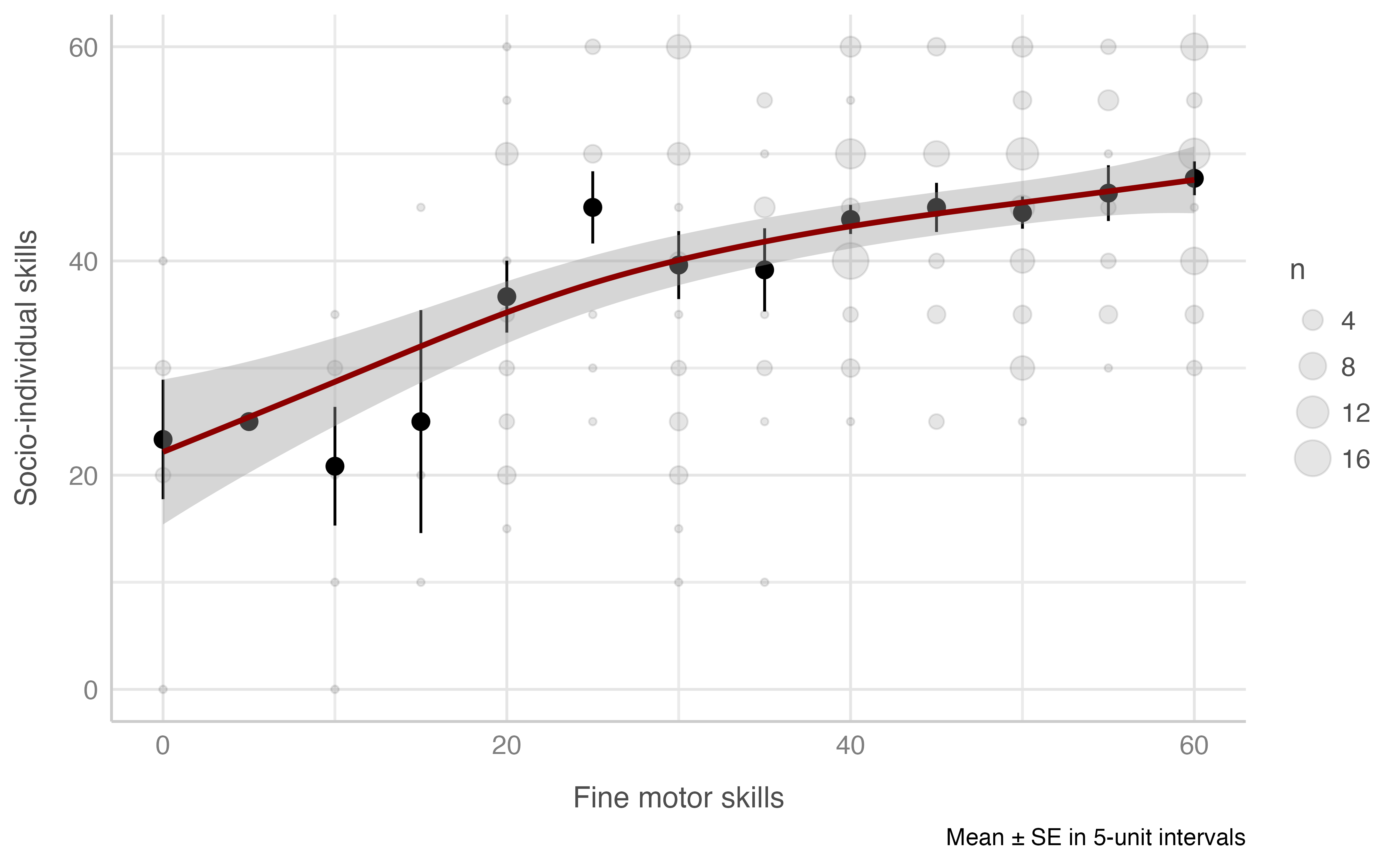
mgcv::gam(formula = socio_individual_total ~ s(motora_fina_total),
data = dataset[n_evaluacion == 1],
method = "REML") |>
summary()
#>
#> Family: gaussian
#> Link function: identity
#>
#> Formula:
#> socio_individual_total ~ s(motora_fina_total)
#>
#> Parametric coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 42.1581 0.7452 56.57 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Approximate significance of smooth terms:
#> edf Ref.df F p-value
#> s(motora_fina_total) 2.406 3.006 18.72 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> R-sq.(adj) = 0.192 Deviance explained = 20.1%
#> -REML = 900.4 Scale est. = 129.95 n = 234Problem solving score & Communication score
Model: resolucion_problemas_total ~ comunicacion_total
plot_gam(data = dataset[n_evaluacion == 1],
x = comunicacion_total,
y = resolucion_problemas_total,
ylab = "Problem solving",
xlab = "Communication",
round_to = 5,
method = "REML")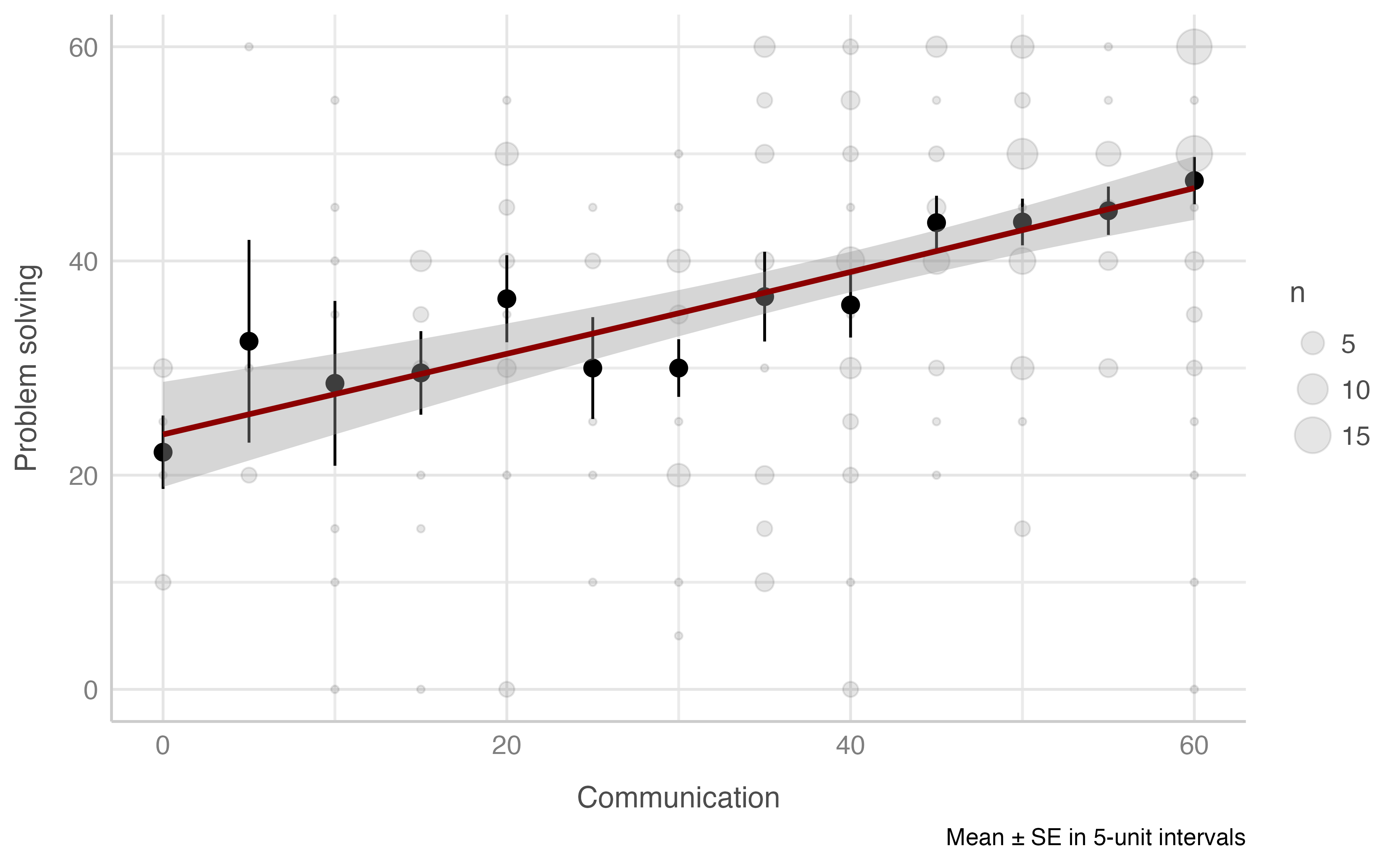
mgcv::gam(formula = resolucion_problemas_total ~ s(comunicacion_total),
data = dataset[n_evaluacion == 1],
method = "REML") |>
summary()
#>
#> Family: gaussian
#> Link function: identity
#>
#> Formula:
#> resolucion_problemas_total ~ s(comunicacion_total)
#>
#> Parametric coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 38.8034 0.9331 41.59 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Approximate significance of smooth terms:
#> edf Ref.df F p-value
#> s(comunicacion_total) 1.073 1.143 40.14 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> R-sq.(adj) = 0.164 Deviance explained = 16.8%
#> -REML = 951.44 Scale est. = 203.75 n = 234Problem solving score & Gross motor skills score
Model: resolucion_problemas_total ~ motora_gruesa_total
plot_gam(data = dataset[n_evaluacion == 1],
x = motora_gruesa_total,
y = resolucion_problemas_total,
ylab = "Problem solving",
xlab = "Gross motor skills",
round_to = 5,
method = "REML")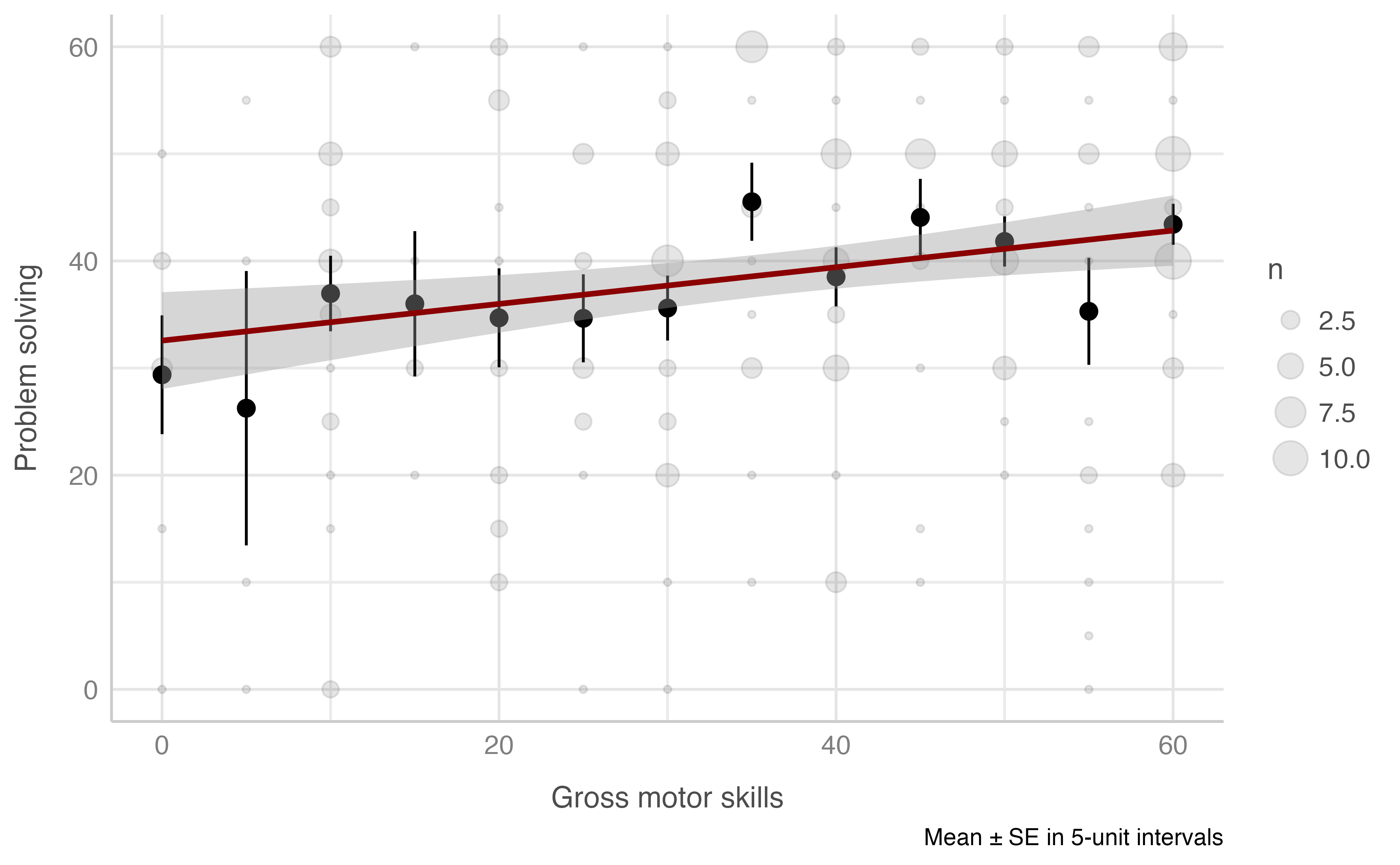
mgcv::gam(formula = resolucion_problemas_total ~ s(motora_gruesa_total),
data = dataset[n_evaluacion == 1],
method = "REML") |>
summary()
#>
#> Family: gaussian
#> Link function: identity
#>
#> Formula:
#> resolucion_problemas_total ~ s(motora_gruesa_total)
#>
#> Parametric coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 38.803 1.004 38.66 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Approximate significance of smooth terms:
#> edf Ref.df F p-value
#> s(motora_gruesa_total) 1.001 1.002 9.034 0.00294 **
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> R-sq.(adj) = 0.0334 Deviance explained = 3.75%
#> -REML = 968.31 Scale est. = 235.7 n = 234Problem solving score & Socio-individual skills score
Model: resolucion_problemas_total ~ socio_individual_total
plot_gam(data = dataset[n_evaluacion == 1],
x = socio_individual_total,
y = resolucion_problemas_total,
ylab = "Problem solving",
xlab = "Socio-individual skills",
round_to = 5,
method = "REML")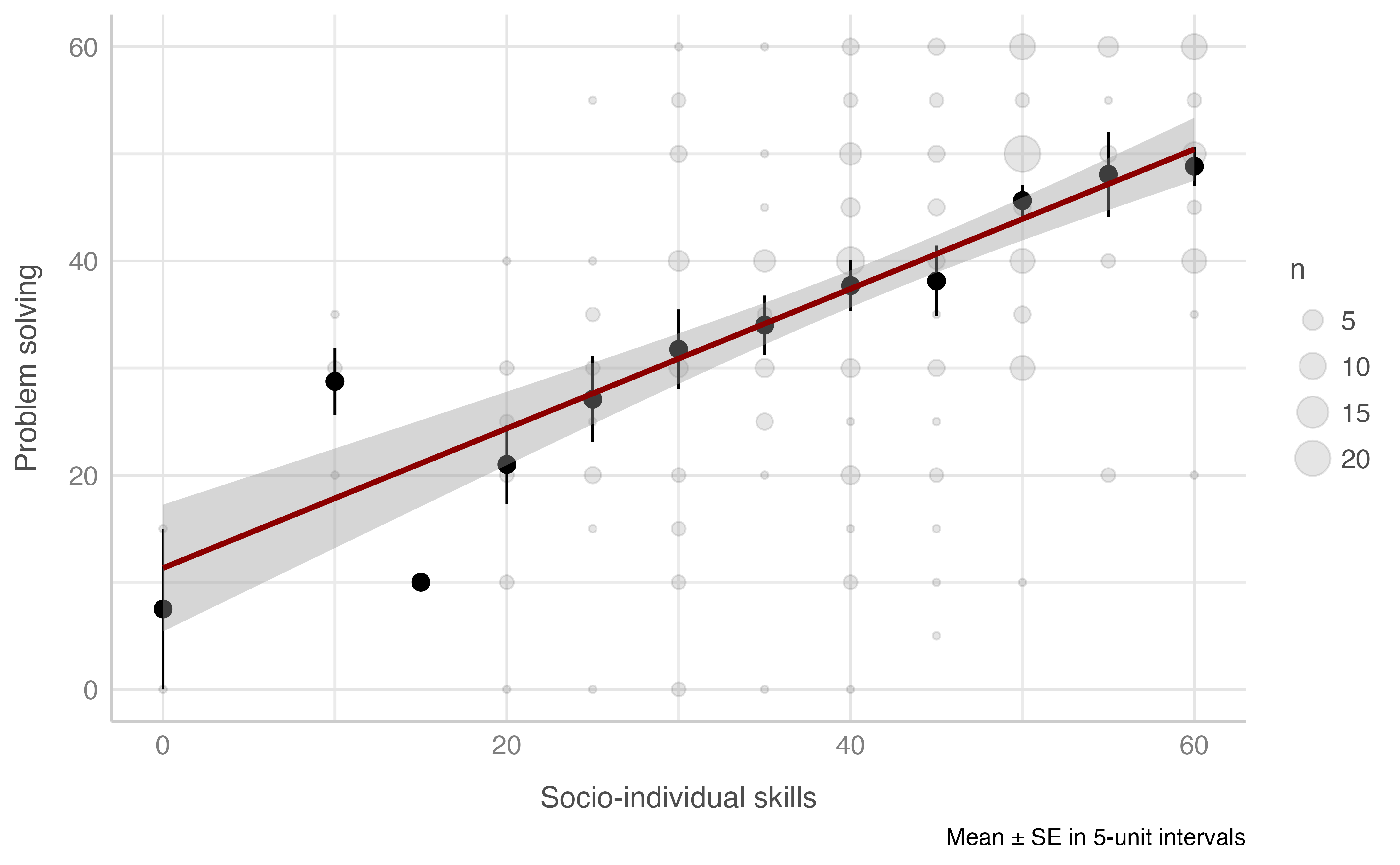
mgcv::gam(formula = resolucion_problemas_total ~ s(socio_individual_total),
data = dataset[n_evaluacion == 1],
method = "REML") |>
summary()
#>
#> Family: gaussian
#> Link function: identity
#>
#> Formula:
#> resolucion_problemas_total ~ s(socio_individual_total)
#>
#> Parametric coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 38.8034 0.8679 44.71 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Approximate significance of smooth terms:
#> edf Ref.df F p-value
#> s(socio_individual_total) 1.001 1.002 90.16 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> R-sq.(adj) = 0.277 Deviance explained = 28%
#> -REML = 934.6 Scale est. = 176.27 n = 234Adjusting for evaluation
Communication score & chronological age (in months)
unadjusted <- mgcv::gam(formula = comunicacion_total ~ s(edad_cronologica_meses),
data = dataset[n_evaluacion == 1],
method = "REML")
adjusted <- mgcv::gam(formula = comunicacion_total ~ profesional_id + s(edad_cronologica_meses),
data = dataset[n_evaluacion == 1],
method = "REML")
summary(unadjusted)
#>
#> Family: gaussian
#> Link function: identity
#>
#> Formula:
#> comunicacion_total ~ s(edad_cronologica_meses)
#>
#> Parametric coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 39.4017 0.9242 42.63 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Approximate significance of smooth terms:
#> edf Ref.df F p-value
#> s(edad_cronologica_meses) 5.079 6.142 14.54 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> R-sq.(adj) = 0.276 Deviance explained = 29.2%
#> -REML = 954.54 Scale est. = 199.86 n = 234
summary(adjusted)
#>
#> Family: gaussian
#> Link function: identity
#>
#> Formula:
#> comunicacion_total ~ profesional_id + s(edad_cronologica_meses)
#>
#> Parametric coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 35.401 7.064 5.012 1.09e-06 ***
#> profesional_id2 2.086 7.110 0.293 0.769
#> profesional_id4 9.331 7.550 1.236 0.218
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Approximate significance of smooth terms:
#> edf Ref.df F p-value
#> s(edad_cronologica_meses) 4.981 6.037 14.48 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> R-sq.(adj) = 0.29 Deviance explained = 31.1%
#> -REML = 946.28 Scale est. = 195.98 n = 234
anova(unadjusted, adjusted, test = "Chisq")
#> Analysis of Deviance Table
#>
#> Model 1: comunicacion_total ~ s(edad_cronologica_meses)
#> Model 2: comunicacion_total ~ profesional_id + s(edad_cronologica_meses)
#> Resid. Df Resid. Dev Df Deviance Pr(>Chi)
#> 1 226.23 45552
#> 2 224.38 44296 1.8498 1255.6 0.03483 *
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
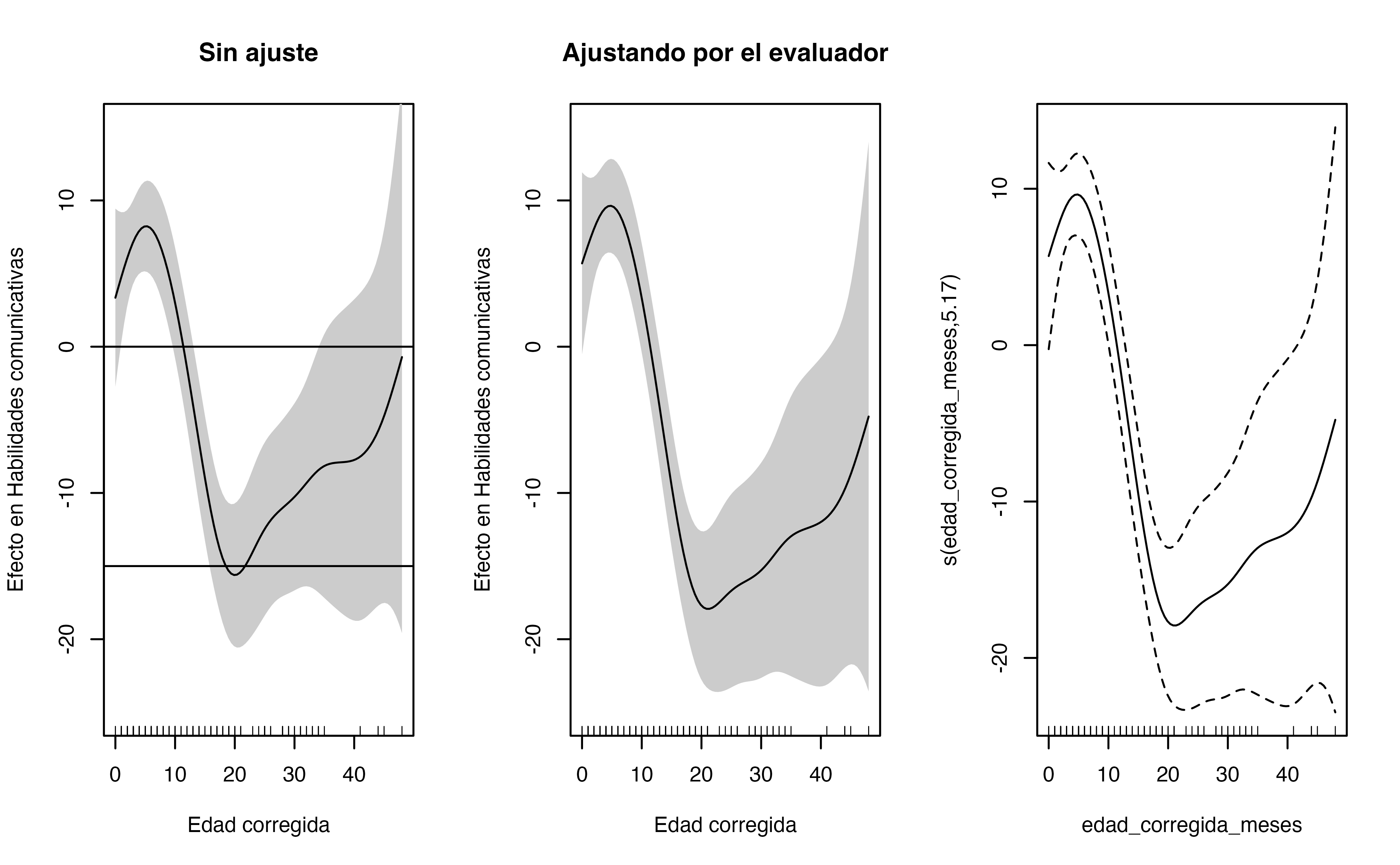
par(mfrow = c(1,2))
plot(unadjusted, shade = TRUE, xlab = "Edad cronológica", ylab = "Efecto en Habilidades comunicativas", seWithMean = TRUE,
main = "Sin ajuste", ylim = c(-25, 15))
abline(h = c(0,-15))
plot(adjusted, shade = TRUE, xlab = "Edad cronológica", ylab = "Efecto en Habilidades comunicativas", seWithMean = TRUE,
main = "Ajustando por el evaluador", ylim = c(-25, 15))
abline(h = c(0,-15))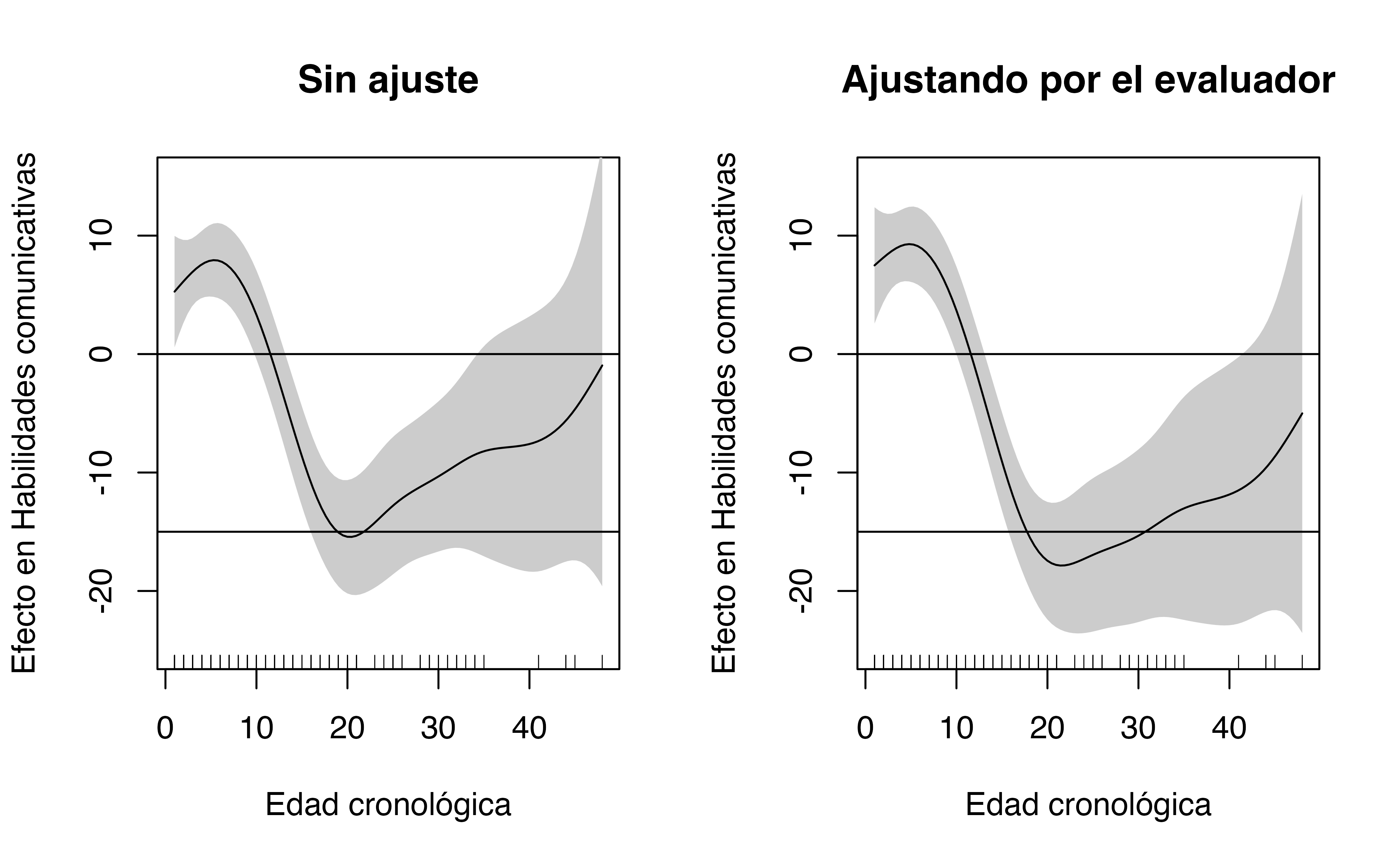
Communication score & corrected age (in months)
unadjusted <- mgcv::gam(formula = comunicacion_total ~ s(edad_corregida_meses),
data = dataset[n_evaluacion == 1],
method = "REML")
adjusted <- mgcv::gam(formula = comunicacion_total ~ profesional_id + s(edad_corregida_meses),
data = dataset[n_evaluacion == 1],
method = "REML")
summary(unadjusted)
#>
#> Family: gaussian
#> Link function: identity
#>
#> Formula:
#> comunicacion_total ~ s(edad_corregida_meses)
#>
#> Parametric coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 39.4017 0.9234 42.67 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Approximate significance of smooth terms:
#> edf Ref.df F p-value
#> s(edad_corregida_meses) 5.252 6.338 14.12 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> R-sq.(adj) = 0.277 Deviance explained = 29.3%
#> -REML = 954.67 Scale est. = 199.55 n = 234
summary(adjusted)
#>
#> Family: gaussian
#> Link function: identity
#>
#> Formula:
#> comunicacion_total ~ profesional_id + s(edad_corregida_meses)
#>
#> Parametric coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 34.994 7.066 4.952 1.44e-06 ***
#> profesional_id2 2.496 7.109 0.351 0.726
#> profesional_id4 9.754 7.563 1.290 0.198
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Approximate significance of smooth terms:
#> edf Ref.df F p-value
#> s(edad_corregida_meses) 5.169 6.25 14.02 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> R-sq.(adj) = 0.291 Deviance explained = 31.3%
#> -REML = 946.4 Scale est. = 195.61 n = 234
anova(unadjusted, adjusted, test = "Chisq")
#> Analysis of Deviance Table
#>
#> Model 1: comunicacion_total ~ s(edad_corregida_meses)
#> Model 2: comunicacion_total ~ profesional_id + s(edad_corregida_meses)
#> Resid. Df Resid. Dev Df Deviance Pr(>Chi)
#> 1 226.04 45446
#> 2 224.16 44175 1.8707 1270.6 0.03403 *
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
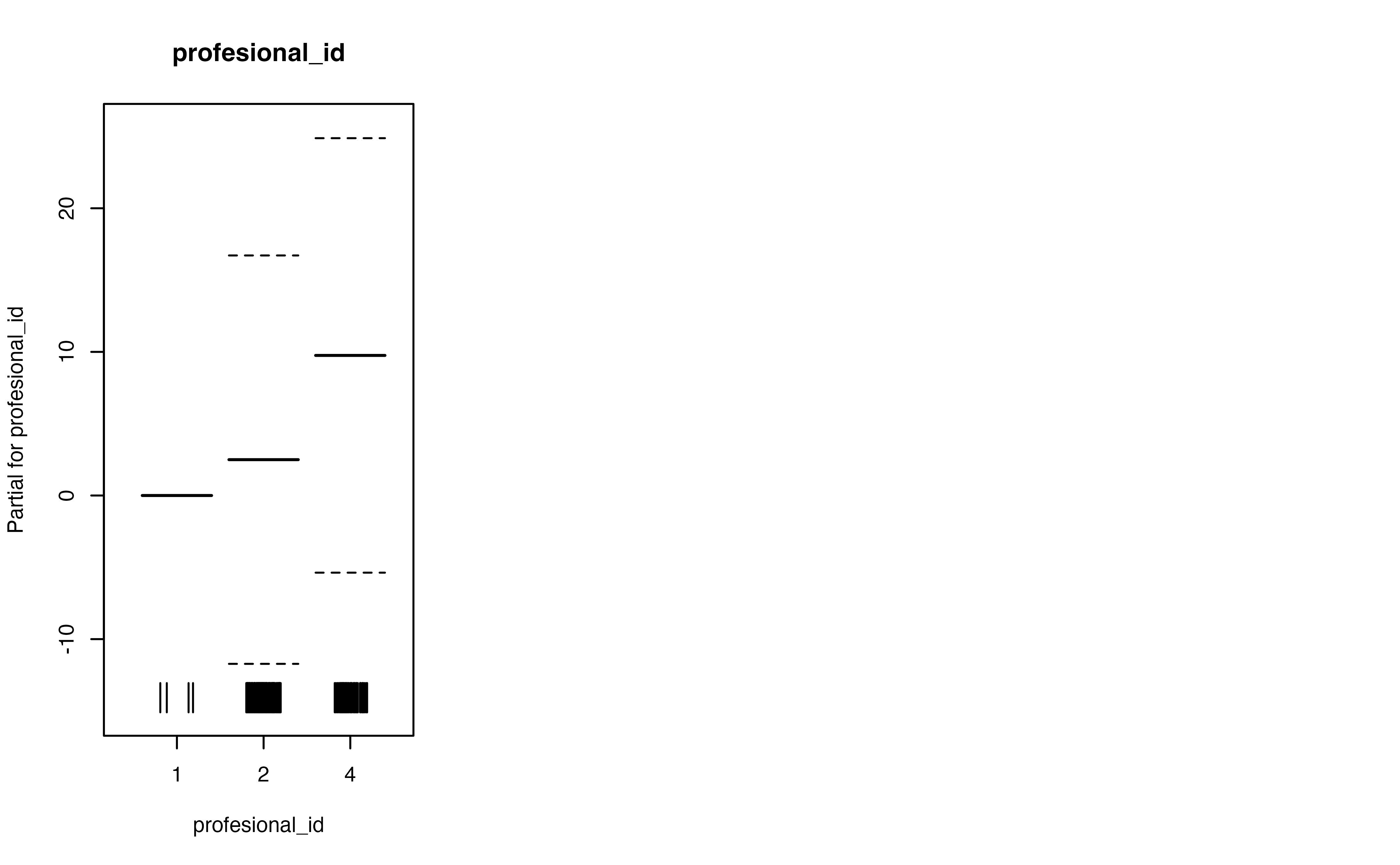
par(mfrow = c(1,3))
plot(unadjusted, shade = TRUE, xlab = "Edad corregida", ylab = "Efecto en Habilidades comunicativas", seWithMean = TRUE,
main = "Sin ajuste", ylim = c(-25, 15))
abline(h = c(0,-15))
plot(adjusted, shade = TRUE, xlab = "Edad corregida", ylab = "Efecto en Habilidades comunicativas", seWithMean = TRUE,
main = "Ajustando por el evaluador", ylim = c(-25, 15))
plot(adjusted, all.terms = TRUE)